
컴공댕이 공부일지
[ Alchmist 8주차 ] chapter 06 차원 축소 [ PCA, LDA, SVE, NMF ] 본문
[ Alchmist 8주차 ] chapter 06 차원 축소 [ PCA, LDA, SVE, NMF ]
은솜솜솜 2023. 11. 16. 16:11참고 교재 - (위키북스) 파이썬 머신러닝 완벽 가이드 개정 2판
01. 차원 축소 (Dimension Reduction) 개요
많은 피처로 구성된 다차원 데이터 세트의 차원을 축소해, 새로운 차원의 데이터 세트를 생성하는 것
변수의 개수 = 차원의 개수
n개의 독립 변수들이 하나의 공간에 표현되려면, 공간이 n차원이여야 한다.
즉, 차원이 증가할수록 데이터 표현 공간이 복잡해진다.
그래서, 모델링이 어려워지기 때문에 기존 변수를 조합하는 차원 축소 기법을 사용하는 것이다.
ㅡ
차원이 증가할수록, 데이터 포인트 간 거리가 멀어져, 희소한(드문드문한) 구조를 가지게 된다.
피처가 많을 경우, 개별 피처 간 상관관계가 높을 가능성도 크고,
적은 차원에서 학습된 모델보다 예측 신뢰도가 떨어진다.
특히, 선형 회귀와 같은 선형 모델의 경우, 입력 변수 간 상관관계가 높을 경우,
6주차에서 공부했듯이, 다중 공선성 문제로 인해 모델 예측 성능이 저하됩니다.
* 다중 공선성 문제
피처 간의 상관 관계가 매우 높은 경우, 분산이 매우 커져 오류에 민감해지는 현상
그래서, 상관관계가 높은 피처가 많은 경우 독립적인 중요 피처만 남기고 제거 or 규제
많은 피처가 이 문제를 갖고 있다면, PCA로 차원 축소를 수행하는 것도 고려
그래서 차원 축소로 피처 수를 줄여야 직관적 데이터 해석이 가능하다.
또한 차원 축소를 하면, 학습 데이터의 크기도 줄어 학습에 필요한 처리 능력도 줄일 수 있다.
차원 축소는 아래 두 가지로 나눌 수 있다.
- 피처 선택 (특성 선택)
특정 피처에 종속성이 강한 불필요한 피처는 제거
데이터 특징 잘 나타내는 주요 피처만 선택
- 피처 추출 (특성 추출)
기존 피처를 저차원의 중요 피처로 압축해 추출
기준의 피처를 압축 시킨 완전히 다른 새로운 중요 피처가 존재
이 때, 단순 압축이 아닌, 함축적으로 더 잘 설명할 수 있는 또 다른 공간으로 매핑해 추출.
기존 피처가 인지하기 어려웠던 잠재적 요소를 추출하는 것.
ex) 학생의 내신 성적, 모의고사 점수, 봉사활동 내역, 수상 이력등을 보고,
문제 해결력, 학업 성취도 등의 함축된 데이터를 추출해내는 것
차원 축소는 단순한 압축이 아닌, 데이터를 더 잘 설명할 잠재적 요소를 추출하는 것
= 최대한 특징을 살리며 차원을 낮추는 것 !
- 차원 축소의 활용
이미지나 텍스트는 매우 많은 차원을 갖고 있으므로, 차원 축소로 잠재적 의미를 찾아주는데,
이 때 PCA, SVE, NMF 등의 대표적 차원 축소 알고리즘이 활용됨.
- 이미지 분야
수많은 픽셀로 이루어진 이미지 데이터의 잠재적 특성을 피처로 도출해 함축된 형태의 이미지 변환과 압축 수행
원본보다 적은 차원으로 변환된 이 이미지는, 분류 수행 시, 과적합 영향력이 작아져, 예측 성능이 향상된다.
(이미지 자체가 가진 차원의 수는 너무 커서, 비슷한 이미지라도 저긍ㄴ 픽셀의 차이가 잘못된 예측으로 이어진다.)
- 텍스트 분야
또, 덱스트 문서의 숨겨진 의미를 추출하는 데도 자주 사용된다.
차원 축소 알고리즘이 문서 내 단어들의 구성에서 숨겨져있는 의미와 주제를 잠재 요소로 간주하고 이를 찾아낸다.
SVD, NMF는 이러한 Semantic Topic 모델링을 위한 기반 알고리즘으로 사용된다.
02. PCA ( Principle Component Analysis ; 주성분 분석 )
가장 대표적인 차원 축소 기법
여러 변수 간에 존재하는 상관관계를 이용해 이를 대표하는 주성분을 추출해 차원을 축소하는 기법
기존 데이터의 정보 유실이 최소화해야하므로,
PCA는 가장 높은 분산을 가지는 데이터의 축을 찾아 이 축으로 차원을 축소하는데,
이것이 PCA의 주성분이 된다.
즉, *분산이 데이터의 특성을 가장 잘 나타내는 것으로 간주해 이를 보존한다.
분산 : 편차 제곱합의 평균. 흩어진 정도
- PCA의 과정
1) 훈련 세트에서 분산이 최대인 축, 즉 가장 흩어져있는 축, 주성분 찾기
2) 1번 축에 수직인, 분산이 최대인 2번째 주성분 축 찾기
3) 2번 축에 수직인, 분산이 최대인 3번째 주성분 축 찾기
~
4) 데이터 셋의 차원이 n일 때, n개의 주성분 축을 찾을때까지 위의 과정처럼 반복
5) 주성분 모두 찾은 후, d개의 주성분으로만 이루어진 평면에 투영해(like.정사영) d차원으로 축소

이처럼 PCA는 원본 데이터 피처 개수에 비해 매우 작은 주성분으로
원본 데이터의 변동성(흩어진 정도)을 설명할 수 있는 분석법이다.
- 선형대수 관점의 PCA
입력 데이터의 공분산 행렬을 고유벡터와 고유값으로 분해하고,
고유벡터를 활용해 입력 데이터를 선형 변환하는 것
- 공분산 행렬과 기타 개념들
공분산 행렬 (Covariance Matrix)
: 변수들 사이의 공분산을 행렬 형태로 나타낸 것.
*공분산 : 두 변수의 상관관계를 측정하는 척도
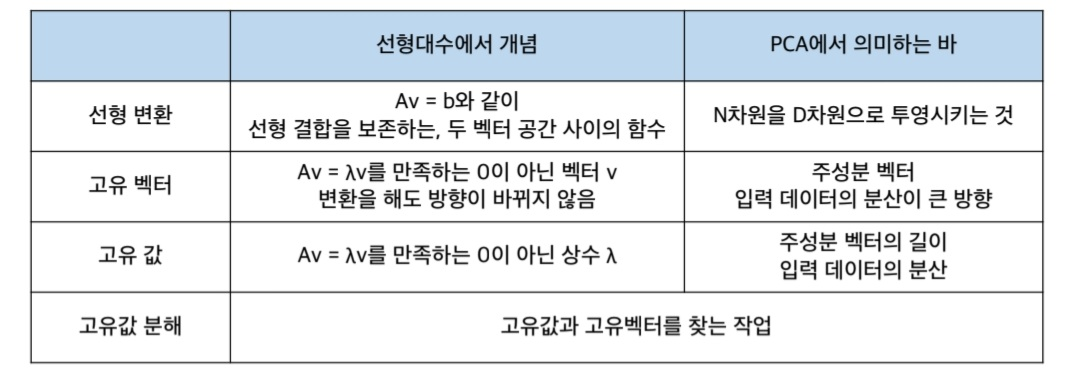
선형 변환
: Av = b ( 행렬 A를 이용해 벡터 v를 b로 변환 ) => 백터 v를 다른 벡터 b로 매핑하는 것.
특정 벡터를 하나의 공간에서 다른 공간으로 투영하는 개념( = 행렬을 공간으로 가정 ! )
고유벡터
: 선형변환을 해도, 결과가 자기 자신의 상수배가 되는 벡터
( 즉, 행렬을 곱해도 방향 변화는 없이 크기만 변하는 벡터 )
PCA의 주성분 벡터로서, 데이터의 분산이 큰 방향
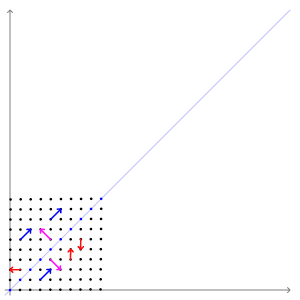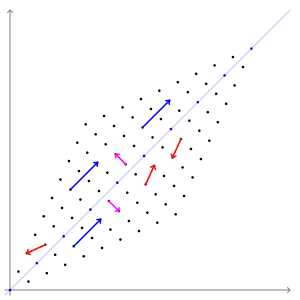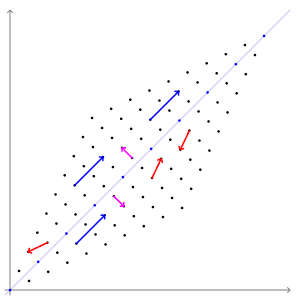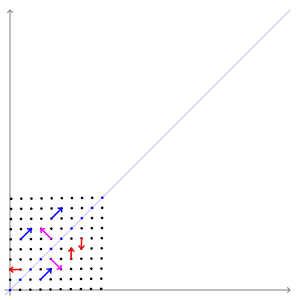
고유값 (eigenvalue)
: Av = λv인 상수 λ , v가 고유벡터
고유벡터의 크기, 입력 데이터의 분산
- PCA 구현 스텝
(주피터 노트북 참고)
1) 입력 데이터 세트의 공분산 행렬 생성
2) 공분산 행렬의 고유벡터와 고유값을 계산
3) 고유값이 가장 큰 순으로 PCA 변환 차수만큼의 고유벡터를 추출
4) 고유값이 가장 큰 순으로 추출된 고유벡터를 이용해, 새롭게 데이터 변환

선대에서 배웠던 개념 총동원... PCA를 선형대수학 적으로 접근해
예제를 갖고 고유벡터, 고유값을 계산해보며 공부해보았다 !!
03. LDA ( Linear Discriminant Analysis ; 선형 판별 분석법 )
분류를 용이하게 해주는 차원 축소 기법
특정 공간 상에서 클래스 분리를 최대화하는 축을 찾기 위해
클래스 간 분산과 클래스 내부 분산의 비율을 최대화하는 방식으로 차원을 축소
클래스 간 분산은 최대한 크게, 클래스 내부의 분산은 최대한 작게 가져가는 방식
공분산 행렬이 아닌, 클래스 간 분산과 클래스 내부 분산 행렬을 생성해, 고유 벡터를 구해 데이터를 투영
- LDA 스텝
1. 클래스 내부 / 간 분산 행렬을 구한다.
두 개의 행렬은 데이터의 결정 값 클래스별로 개별 피처의 평균 벡터를 기반으로 구함.
2. 찾은 두 개의 행렬을 고유벡터로 분해
3. 고유값이 가장 큰 순으로 LDA 변환 차수만큼의 개수로 추출
4. 고유값이 가장 큰 순으로 추출된 고유벡터를 이용해 새롭게 입력받은 데이터를 변환
04. SVD ( Singular Value Decomposition ; 특이값 분해 )
행렬이 어떻게 분해되는지를 파악해 차원을 축소시키는 방법
PCA와 유사한 행렬 분해 기법을 이용하는데, PCA는 정방행렬만을 고유벡터로 분리할 수 있지만.
SVD는 행과 열과 크기가 다른 행렬에도 적용할 수 있음
05. NMF( Non - Negative Matrix Factorization )
음수를 포함하지 않는 행렬의 행렬 분해
낮은 랭크를 통한 행렬 근사 방식의 변형
원본 행렬 내의 모든 원소 값이 양수로 보장되면,
더 간단하게 두 개의 기반 양수 행렬로 변환하는 기법
참고한 블로그. 잘 설명해두셔서 이해하기 좋았어욥 :)
https://blog.naver.com/paragonyun/222465847517
머신러닝 - 차원 축소 (PCA, LDA, SVD, NMF)
안녕하세요~ 오늘 알아볼 것은 차원축소입니다. 실제로 우리가 데이터를 받았을 때, 여러가지 피쳐들로 이...
blog.naver.com



