
컴공댕이 공부일지
[ Alchmist 7주차 ] chapter 05 (9) ~ (11) [ 회귀 실습 : 자전거 대여 수요 예측, 주택 가격 예측 ] 본문
[ Alchmist 7주차 ] chapter 05 (9) ~ (11) [ 회귀 실습 : 자전거 대여 수요 예측, 주택 가격 예측 ]
은솜솜솜 2023. 11. 14. 12:47참고 교재 - (위키북스) 파이썬 머신러닝 완벽 가이드 개정 2판
01. 자전거 대여 수요 예측
- 함수 정리
.subpots()
: 여러 개의 그래프를 한 번에 표현
barplot()
: 막대그래프 형태로 시각화
hist()
: 빈도를 시각적 막대그래프로 표현하는 히스토그램을 그려주는 함수
tight_layout()
: 요소 간격을 조종해 레이어를 최적화
- RMSLE
MSE (오차의 제곱 평균)
RMSE (mse에 루트)
RMSLS (rmse에 로그 추가)
모두 값이 0에 가까울수록 좋은 성능.
그러나, 스코어링을 할 땐, neg 활용
log1p() 함수( log(x+1) )를 활용해 로그 변환해 오버/언더플로 오류를 해결한다.
expm1() 함수로 원래 스케일로 다시 돌릴 수 있다.
특징
- 로그값을 사용하므로 변동 폭이 작아 데이터 이상치에 덜 민감함
- 절대 오차 아닌, 상대 오차 값을 측정
- under estimation에 큰 패널티 부여
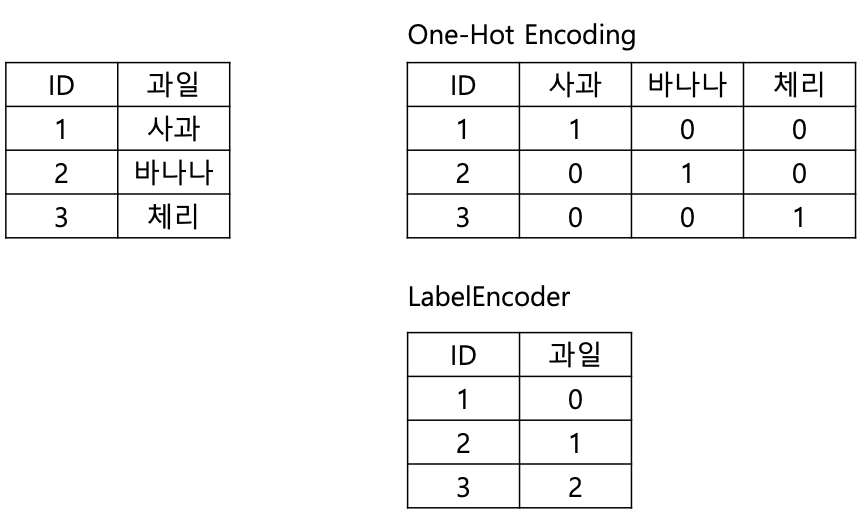
- 원 핫 인코딩
카테고리형 데이터를 컴퓨터가 이해하기 쉬운 형태로 변환하는 기법
회귀는 카테고리성 피처들을 원 핫 인코딩으로 변환해주어야 좋은 성능이 나올 수 있다.
아니면 카테고리 숫자값이 회귀 계수 연산에 영향을 주게 된다.
행 형태의 피처값을 열 형태로 변환한 뒤
피처값 인덱스에 해당하는 칼럼에는 1로, 나머지 칼럼에는 0으로 표시하는 방식.
pandas의 get_dummies()
범주형 데이터를 원핫인코딩하여 더미 변수로 변환해줌
NULL값은 모든 인코딩이 0이다 !
[ 주요 파라미터 ]
data: 적용할 데이터
prefix: 생성할 더미 데이터의 컬럼이름
prefixsep: `default=''`
dummpy_na: NaN도 포함시킬지
columns: 대상이 되는 컬럼
dtype: 새로운 columns의 데이터 타입
get_dummies()
- 왜곡된 분포
데이터 셋은 정규 분포 형태를 지향하며, 분석에서 정확한 값을 얻기 위해 변환을 하는데,
이 중 로그 변환이 가장 많이 사용된다고 지난 세션에서 공부했었다.
원래 값에 로그를 취해, 정규 분포에 가까운, 왜곡 정도를 향상시킨 데이터 셋을 얻도록 한다.
02. 주택 가격 예측
바람직한 머신러닝 모델은 한번에 완벽하게 모델을 만드는 것이 아니라,
대략적으로 그때그때 필요한 데이터를 가공하고 모델을 최적화해나가면서
점진적으로 더 좋은 모델을 만들어 나가는 것이다.
- alpha
회귀 계수의 값의 크기를 제어하는 튜닝 파라미터
이 값을 최적화해야 회귀 모델의 성능이 향상된다.
알파값이 크면, 회귀 계수 w 작게
알파값이 작을 땐, w가 커져도 상쇄 가능
- 예측 결과 혼합
특정 비율로 회귀 모델들의 예측값을 혼합해 최종 회귀 값으로 예측.
혼합 시, 각각의 모델 예측값도가 성능의 개선이 나타난다.
- 피처 분포 / 이상치 가공
피처의 분포도의 왜곡을 skew() 함수로 추출해, 왜곡 정도 높으면, 로그 변환 등을 거친다.
단, 왜곡도 적용 시에 인코딩된 카테고리 숫자 값들은 제외해야 한다.
왜냐면 이미 0 또는 1로 왜곡되어 표기된 값들이라, 왜곡 고려할 필요가 없다.
이상치를 찾는 과정은 어렵지만, 주로 중요도가 높은 피처부터 점검하며 이상치를 찾는 방향으로 수행.
- 스태킹 앙상블
모델의 예측값을 최종 모델의 학습 데이터로 사용 !
기본 모델로부터 예측된 값들이 최종모델의 학습데이터로 사용된다는 것

코드 필사는 주피터 노트북에 있어 티스토리에 복사하지 않음.
이번 실습에서 쓰였던 함수, 개념 등등에서 헷갈리거나, 까먹은 부분만 더 공부해서, 간단히 요약-정리함.



