컴공댕이 공부일지
[ Alchmist 6주차 ] chapter 05 (1) ~ (3) [ 머신러닝 회귀 알고리즘 개요, 단순 선형 회귀, RSS, 경사하강법의 개념 및 Python 구현 ] 본문
[ Alchmist 6주차 ] chapter 05 (1) ~ (3) [ 머신러닝 회귀 알고리즘 개요, 단순 선형 회귀, RSS, 경사하강법의 개념 및 Python 구현 ]
은솜솜솜 2023. 11. 1. 14:33참고 교재 - (위키북스) 파이썬 머신러닝 완벽 가이드 개정 2판
01. 회귀
회귀 분석 ( regression analysis )
데이터 값이 평균 등의 일정한 값으로 돌아가려는 경향을 이용한 통계학 기법
여러 개의 독립변수(다양한 원인들, 피처)와 한 개의 종속변수(결과, 결정 값) 간의 상관 관계를 모델링하는 기법
이때, 독립변수의 값에 영향을 미치는 회귀 계수들이 존재함.
주어진 피처와 결정 값 데이터 기반에서 학습을 통해
최적의 회귀 계수를 찾아내는 것이 머신러닝 회귀 예측의 핵심

*지도학습 : 정답이 있는 데이터를 활용해 모델을 학습시키는 방법
⬇⬇가장 많이 사용되는 회귀
선형 회귀
실제 값과 예측 값의 차이(오류의 제곱 값)를 최소화하는 직선형 회귀선을 최적화하는 방식
오류 = 실제값 - 예측값
규제 방식에 따라 다시 여러 유형으로 나뉨
( 규제 : 일반적 선형 회귀의 과적합 문제를 해결하기 위해 회귀 계수에 패널티 적용하는 것 )
과적합 : 모델이 학습 데이터에만 과도하게 최적화되어, 실제 예측을 다른 데이터로 수행할 땐 예측 성능이 과도하게 떨어지는 것.
대표적 선형 회귀 모델
- 일반 선형 회귀 규제 적용 x
예측값과 실제값의 RSS(Resicual Sum of Squares : 제곱들의 합 )를 최소화할 수 있도록 회귀 계수 최적화
- 릿지 (Ridge) L2 규제 추가
L2 규제 : 상대적으로 큰 회귀 계수 값의 예측 영향도를 감소시키려 회귀 계수값을 더 작게 만드는 규제 모델
- 라쏘 (Lasso) L1 규제 추가
L1 규제 (=피처 선택 기능) : 예측 영향력이 작은 피처의 회귀 계수를 0으로 만들어, 회귀 예측 시 피처가 제외시킴
- 엘라스틱넷 (ElasticNet) L1, L2 함께 결합
주로 피처가 많은 데이터 셋에 적용
L1으로 피처 갯수 줄이고, L2로 계수값 크기 조정
- 로지스틱 회귀 (Logistic Regression) 분류에 사용되는 선형 모델
매우 강력한 분류 알고리즘
이진 분류 뿐 아니라 희소 영역의 분류(ex.텍스트 분류) 영역에서 뛰어난 예측 성능 보임
02. 단순 선형 회귀를 통한 회귀 이해
단순 선형 회귀 : 독립변수와 종속변수가 각각 하나인 선형 회귀

잔차 (남은 오류)
: 실제값과 회귀 모델 차이에 따른 오류
최적의 회귀 모델
= 전체 데이터의 잔차(오류값)의 합이 최소가 되는 모델
= 오류값 합이 최소가 될 수 있는 최적의 회귀 계수 찾기
오류값은 음양 모두 가능! 그래서 단순 합을 계산하면 안됨.
2가지 오류 합 계산 법
- Mean Absolute Error : 절댓값 취해 더하기
- Residual Sum of Square : 제곱을 더하기

머신 러닝 회귀 알고리즘이란,
데이터를 계속 학습하며 비용함수가 반환하는 값 즉, 오류값을 지속해서 감소시키고
최종적으로 더 이상 감소하지 않는 최소의 오류 값을 구하는 것
RSS(오류, 비용함수)를 최소로 하는 회귀 계수 w를 학습을 통해 찾는 것이 머신러닝 회귀의 핵심 !!
03. 비용 최소화하기 - 경사 하강법 (Gradient Descent)
점진적인 하강으로 비용 함수 최소로 만드는 W값 업데이트하며 최소의 오류값을 가지는 W 파라미터 찾기
경사하강법 : 오류가 작아지는 방향으로 회귀 계수 W값을 보정해나가는 방식
경사하강법의 개요
비용 함수가 포물선 형태의 2차 함수라 가정.
비용함수 식을 미분해, 미분값 즉, 기울기가 감소하는 방향으로 w를 업데이트함
마침내 기울기가 감소하지 않는 지점 = 비용 함수가 최소인 지점. 그 때의 w 반환.

딥러닝의 기반인 신경망에서도 경사 하강법을 통한 학습을 수행한다.
그만큼 경사 하강법은 머신러닝에서 중요한 개념이니
아래의 수식이 이해 안되더라도 경사하강법의 의미를 이해해보자 !

경사 하강법의 일반적인 프로세스
step 1 ) w1, w0을 임의 값으로 설정, 첫 비용함수 값 계산
step 2 ) w1, w0을 업데이트한 후 비용함수 값 다시 계산
step 3 ) 비용 함수가 감소하는 방향으로 주어진 횟수만큼 step 2를 반복, w1과 w2를 계속 업데이트
경사 하강법의 구현 (Python)
단순 선형 회귀로 예측할 만한 데이터 세트 만들기
import numpy as np
import matplotlib.pyplot as plt
%matplotlib inline
np.random.seed(0)
# y = 4x+6 근사. (w1=4, w0=6). 노이즈 위해 임의의 값 만들기.
x=2*np.random.rand(100,1)
y=6+4*x+np.random.randn(100,1)
#x,y 데이터 세트 산점도로 시각화
plt.scatter(x,y)
numpy random
np.random.rand(n,m)
:0~1의 균일분포 *표준정규분포 난수를 (n,m) 행렬로 생성
np.random.randn(n,m)
:평균 0, *표준편차 1의 가우시안 표준정규분포 난수를 (n,m) 행렬로 생성
*표준 편차 : root(편차 제곱의 평균)
*표준 정규 분포 : 평균이 0, 표준편차가 1인 정규분포 / https://www.youtube.com/watch?v=cUDr0BydCGg (참고 영상)
함수 구현
get_cost(실제값, 예측값)
: R(w) 함수값을 반환하는 함수
# 실제값과 예측값을 인자로 받아 RSS를 계산해주는 get_cost()함수 구현
def get_cost(y, y_pred) :
N = len(y)
cot = np.sum(np.square(y-ypred))/N
return cost
get_weight_updates(w1, w0, x, y, learning_rate=n)
: w0, w1을 모두 0으로 초기화한 후 업데이트값(편미분값)을 구하는 함수
# w값 업데이트 함수
def get_weight_updates(w1, w0, x, y, learning_rate=0.01) :
N=len(y)
#업데이트값을 기존값과 같은 사이즈의 0으로 초기화
w1_updates = np.zeros_like(w1)
w2_updates = np.zeros_like(w0)
#예측 배열 계산
y_pred = np.dot(x, w1.T) + w0
# 실제값-예측값
diff = y-y_pred
# 내적 연산 위한 w0 행렬 생성
w0_factors = np.ones(N,1) # ones((n,m)) : n행 m열의 1로 채워진 ndarray 반환
# w값 업데이트 (편미분값 계산)
w1_update = -(2/N)*learning_rate*(np.dot(x.T, diff)) # x * 오류값
w0_update = -(2/N)*learning_rate*(np.dot(w0_factors.T, diff)) # 오류값
return w1_update, w0_update
np.zeros_like(x)
: 변수 x만큼의 사이즈인 0 으로 가득 찬 Array를 반환
RSS 식을 참고하면, ∑( y - ( w0+w1*x ) )^2 / N
위 식의 시그마를 계산하면, 예측값은 w0 + w1*x1 + w1*x2 + ... + w1*xn이다.
이는 x 배열과 w1 배열의 내적값과 같다 !
그래서 일차원 배열인 둘을 내적한다. (한 배열을 전치시키면 내적 가능!)
.dot( A, B ) : 행렬 A,B 내적
.T : 행렬 전치
gradient_descent_steps(x, y, iters=10000)
: iters만큼 반복적으로 w1, w0 업데이트 (새로운 값 = 기존값 - 편미분값)
def gradient_descent_steps(x, y, iters=10000) :
#w0, w1 0으로 초기화
w0 = np.zeros((1,1))
w1 = np.zeros((1,1))
for i in range(iters) :
w1_updates, w0_updates = get_weight_updates(w1, w0, x, y, learning_rate=0.01)
w1 = w1-w1_updates
w0 = w0-w0_updates
return w1, w0
경사 하강법 구현 (예측 오류 계산)
w1, w0 = gradient_descent_steps(x, y, iters=10000)
print("w1:{0:.3f} w0:{1:.3f}".format(w1[0,0], w0[0,0]))
y_pred = w1[0,0]*x + w0
print('경사 하강법 총 코스트 : {0:.4f}'.format(get_cost(y,y_pred)))w1:3.968 w0:6.222
경사 하강법 총 코스트 : 104.7303
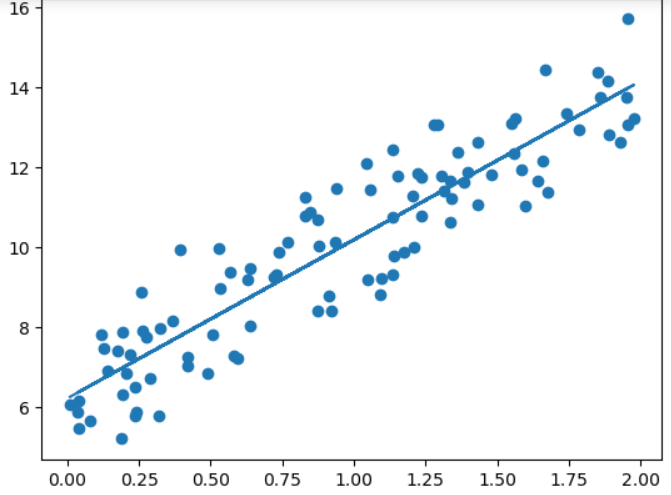
최종 회귀선 그리기
#회귀선 그리기
plt.scatter(x,y)
plt.plot(x,y_pred)